2026-05-24
Carbon: The DNA Foundation Model That Makes Evo 2 Accessible to Biotech SMEs
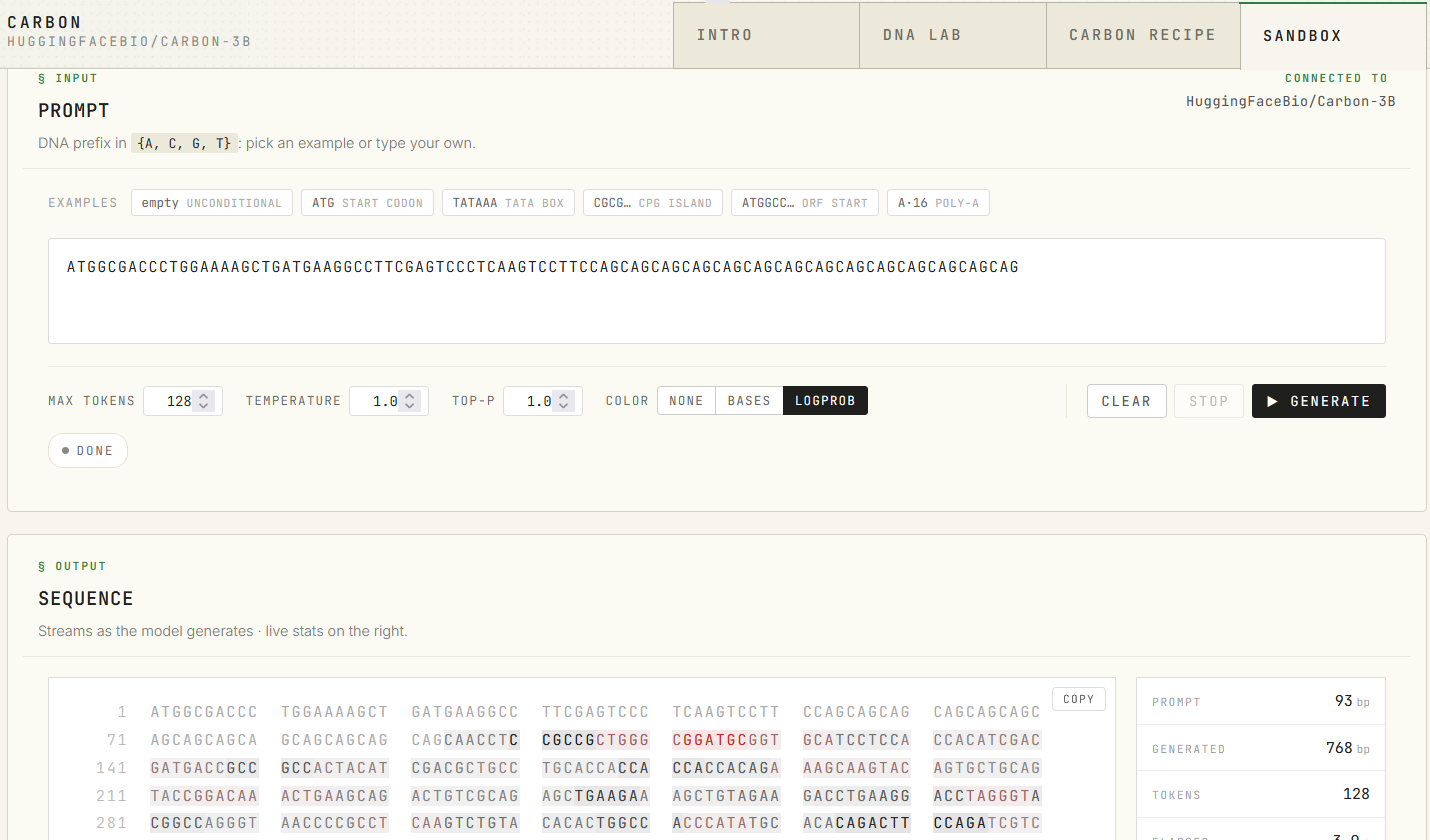
Two months ago, Evo 2 proved AI could read the genome. This week, Carbon proved you no longer need a GPU cluster to use it.
The test: HTT exon 1, 14 CAG repeats
I gave Carbon-3B the first 93 bases of human HTT exon 1 (Huntingtin), including the 14 CAG repeats — the polyQ tract that defines Huntington's disease.
Carbon's very first generated codon was CAA — the canonical synonymous codon that closes polyQ tracts in real HTT. The model then immediately produced CCT-CCG-CCG, the proline-rich region that follows polyQ in the actual gene.
768 bp in 3.9 seconds, on the public Hugging Face Space. No fine-tuning. No prior knowledge of HTT. Just structural pattern learning from raw DNA.
That is the point.
Carbon: Evo 2's recipe, rebuilt for accessibility
Carbon was released this week by Hugging Face, Zhongguancun Academy, and TIGEM.
Same paradigm as Evo 2 — treat DNA as a language, train a large autoregressive model on it (detailed breakdown of Evo 2 here) — but the recipe was rebuilt around one question: can we hit the same frontier without needing a cluster to run it?
The numbers
The answer is yes.
- Carbon-3B matches Evo 2-7B across the seven zero-shot benchmarks reported in the paper, with half the parameters and 150× faster inference.
- Carbon-8B improves on every task, with the biggest jump on long-context retrieval — up to 786 kbp.
What matters as much as the weights: the full recipe is open
What I find even more interesting than the weights is what was released alongside them. The full recipe is open:
- The training code
- The Carbon Pretraining Corpus
- The ablations
- A clean seven-benchmark evaluation suite that runs Carbon, Evo 2, and GENERator behind a single flag
The DNA evaluation landscape was scattered across half a dozen papers. It just got a common reference point.
What this concretely changes for biotech and pharma
A 5-person biotech can now test a DNA foundation model on its own sequences without renting an H100 cluster.
- Variant interpretation
- Rare disease diagnostics
- Regulatory sequence design
All of this just became accessible to teams that could not afford to run Evo 2-40B.
Evo 2 proved the science. Carbon makes it usable.
That's the real shift this week. The entry ticket for seriously experimenting with a DNA foundation model just went from a cloud budget to a consumer GPU — or a free Space.
If you're running a biotech or pharma project and want to evaluate what a model like Carbon can bring to your sequences, let's take 30 minutes to discuss.