2026-04-28
95 % d'accuracy qui tombe à 58 % : pourquoi les modèles deep learning échouent sur signal bio
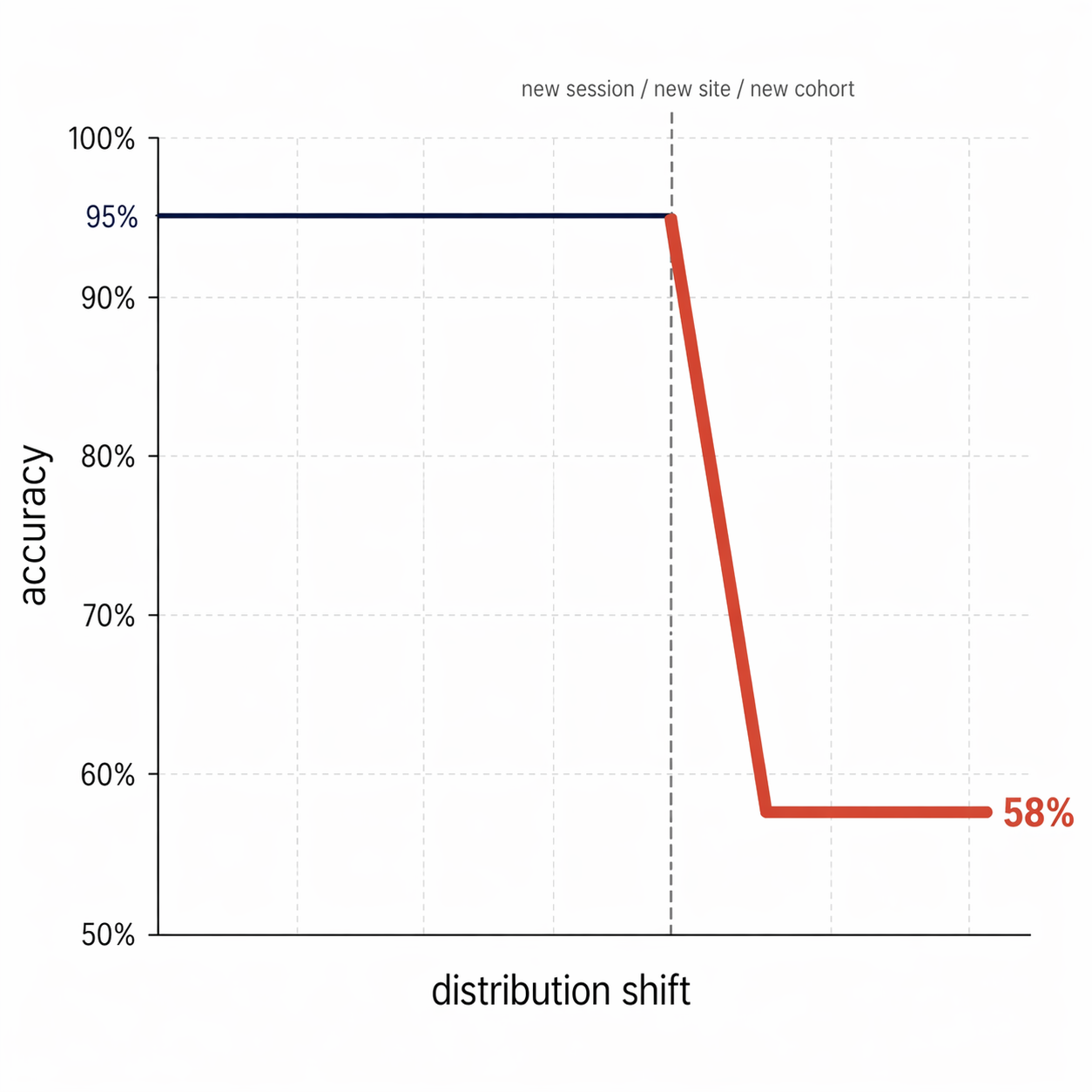
Un modèle à 95 % d'accuracy qui tombe à 58 % en changeant de manip
J'ai vu le scénario. Et c'était prévisible.
Mon terrain c'était les signaux neuronaux. Mais le problème dépasse largement l'électrophysiologie. Il touche tous les modèles de deep learning appliqués à du signal biologique : ECG, EEG, signaux de capteurs, imagerie dynamique, data précliniques.
Le test set ment souvent
Le score sur le test set ment, parce que le modèle n'apprend pas la biologie. Il apprend la signature de votre session d'acquisition.
Tant que les segments de test viennent des mêmes sessions que les segments d'entraînement, le modèle ne fait que reconnaître un contexte qu'il a déjà vu. La performance affichée mesure une mémorisation, pas une compréhension.
Ce qui change quand un seul curseur bouge
- Vous changez de device : le spectre de bruit se décale
- Vous changez de préparation ou de patient : l'amplitude varie
- Vous changez de site, de centre, de cohorte : la distribution explose
- Vous changez d'annotateur : les labels bougent
Le modèle n'a pas appris à différencier le signal du contexte. Il a cartographié un contexte précis.
La seule métrique qui compte vraiment
Pour un modèle destiné à la production ou à un essai clinique, la métrique qui compte n'est pas l'accuracy in-distribution.
C'est la généralisation cross-session, cross-sujet, cross-site.
C'est elle qui détermine si le modèle survit au passage du laboratoire au monde réel, d'un protocole de recherche à un usage clinique, d'une cohorte pilote à un déploiement multi-centres.
Trois changements qui changent la pratique
1. Splitter par sessions entières, pas par segments
La frontière train/test doit isoler des sessions, des sujets ou des sites complets. Si un seul segment d'une session se retrouve à la fois en train et en test, le leak est déjà là, et l'accuracy mesurée est un mirage.
2. Faire valider les features apprises par un expert du domaine
Grad-CAM, ondelettes, saliency maps : les outils existent pour ouvrir la boîte noire. Mais la lecture biologique de ce qu'ils révèlent doit venir d'un expert du signal, pas du data scientist seul. Si le modèle s'appuie sur un artefact de filtrage ou un transitoire d'amplificateur, seul l'œil métier le voit.
3. Traiter le protocole d'acquisition comme une partie de l'architecture
Le protocole d'acquisition compte autant que la couche convolutionnelle qui suivra. Variabilité contrôlée des sessions, randomisation des sites, équilibrage des annotateurs : ces décisions amont conditionnent ce que le modèle peut généraliser. Un modèle robuste en bio commence par un protocole de données robuste.
Où se cache le leak dans votre pipeline ?
Si vous splittez par segments, le leak est presque garanti. Par sessions, il est limité mais pas éliminé. Par sujets, vous testez vraiment la généralisation, mais il faut que les sujets de test viennent de cohortes ou de sites différents pour valider le passage à l'échelle.
Si vous avez un pipeline ML sur signal biologique à auditer, ou un modèle dont vous suspectez qu'il a appris le contexte plutôt que le signal, prenez 30 minutes pour en parler.